

前置说明:这是一个我自己学习Agent Harness开发的一个笔记,上传到这里纯属方便,这个项目叫Odd, 是通过分多个Phase来完成一个能够支持Tools MCP Skill 子agent 任务清单和上下文压缩的Agent框架。我会分多个Phase让AI完成代码,并阅读代码学习
至于为什么用Ado当头图,那当然是因为
Ado统治世界仓库在:https://github.com/GC-SHIRO/Odd.git
一句话总结
给 Agent 加上一个"操作台": 这次的更新加了main.py 让人类能在命令行里和 Agent 持续对话,同时看清 Agent 每一步在想什么、调了什么工具、结果如何。
这一次终于能看到交互效果了,真的很爽
效果图
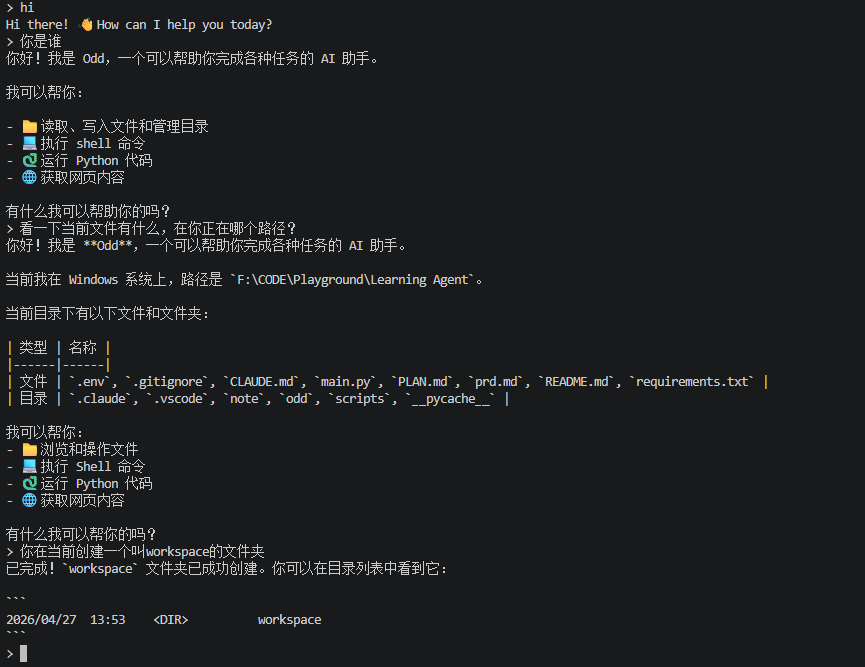
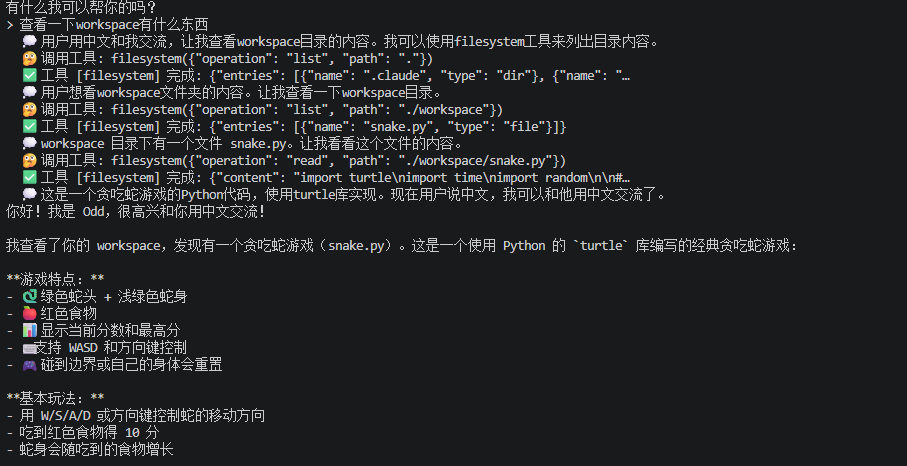
阶段 3 的 Agent 能跑任务,但不能"聊天"
阶段 3 的 Agent.run(task) 是个"一次性任务执行器":
agent.run("列出当前目录文件") # → 返回结果,对话结束
agent.run("再上一级看看") # → 完全忘了上一句说了什么每次 run() 都会新建一条消息链,[System, User任务],之前的历史全丢了。
如果用户想连续对话——比如先问"当前有什么文件",再说"把第一个文件读给我看看"——Agent 根本接不住,因为它没有上下文记忆。
核心零件
1. 给 Agent 增加 chat() 方法(odd/agent.py)
思路:把 ReAct 循环逻辑抽出来,让两种入口共用同一套核心。
run(task) → 新建 [System, User] → _react_loop() → 返回结果
chat(input, history) → 复用 history → 追加 User → _react_loop() → 返回 (结果, 新history)具体逻辑:
chat(user_input, messages=None):
如果
messages为None,新建一条带 System prompt 的空链把用户输入追加进去
调用
_react_loop()返回
(结果, 更新后的消息链),调用方把新消息链存下来,下次再传进来
messages = None
while True:
result, messages = agent.chat(user_input, messages)
# messages 里现在有了 System + User + Assistant + Tool + ... 的完整历史关键设计:_react_loop 是原地修改 messages 的。这样 chat() 不需要做额外的拷贝,消息链在循环中自动增长。
2. 回调机制:让外部"看到" Agent 的内部过程
_react_loop() 跑在 Agent 内部,外部调用方不知道模型什么时候思考了、什么时候调了工具。我们需要一种可观测性机制。
方案对比:
选了 方案 C,给 run() 和 chat() 各加两个可选回调:
def chat(
self,
user_input: str,
messages: Optional[List[Message]] = None,
on_think: Optional[callable] = None, # ← 模型回复后触发
on_tool_result: Optional[callable] = None, # ← 工具执行后触发
):on_think(content, tool_calls, thinking):模型每产生一次回复就触发。thinking是模型推理内容(如果 API 提供了的话)on_tool_result(name, arguments, result):每个工具执行完触发,返回工具名、参数、执行结果
为什么不在 on_tool_result 之前加 on_tool_call?
因为工具调用请求已经在 on_think 的 tool_calls 参数里暴露了,没必要再拆一个回调。保持接口最小。
3. 提取模型的"思考"内容(odd/models/)
最初想在 on_think 里从 content 中解析 <think> 标签来显示思考过程。但这招对 Anthropic API 无效。
原因:Anthropic 返回的是 content blocks 数组,思考内容在 type == "thinking" 的 block 里,根本不会出现在 content 文本中。
# Anthropic 返回结构
resp.content = [
{"type": "thinking", "thinking": "我应该用 shell 工具..."},
{"type": "text", "text": "我来帮你查一下"},
{"type": "tool_use", "name": "shell", "input": {"command": "ls"}},
]原来的解析代码只遍历了 text 和 tool_use,thinking block 被直接丢弃。
修复:
ChatResponse新增thinking: Optional[str]字段AnthropicProvider.chat():遍历 blocks 时,遇到thinking就收集,遇到redacted_thinking就记"[redacted thinking]"OpenAIProvider.chat():顺便兼容 OpenAI 的 reasoning 模型,提取choice.message.reasoning_contenton_think回调增加第三个参数thinking,main.py里优先显示它
4. CLI 入口(main.py)
代码:
def main():
parser = argparse.ArgumentParser(description="Odd Agent CLI")
parser.add_argument(
"--provider",
default="anthropic",
choices=["openai", "anthropic"],
help="模型提供者 (默认: anthropic)",
)
args = parser.parse_args()
# 延迟导入,避免无意义的环境变量检查
from odd.agent import Agent
from odd.tools.registry import registry
# 导入内置工具以触发自动注册
from odd.tools.builtin import shell, filesystem, fetch_url, python # noqa: F401
# 创建模型
if args.provider == "openai":
from odd.models.openai import OpenAIProvider
model = OpenAIProvider()
else:
from odd.models.anthropic import AnthropicProvider
model = AnthropicProvider()
tools = registry.list_tools()
agent = Agent(model=model, tools=tools)
on_think, on_tool_result = make_callbacks()
print("🤖 Odd Agent 已就绪")
print(f" 提供者: {args.provider}")
print(f" 工具: {', '.join(t.spec.name for t in tools) or '无'}")
print(" 输入 'exit' 或 'quit' 退出\n")
messages = None
while True:
try:
user_input = input("> ").strip()
except (EOFError, KeyboardInterrupt):
print("\n再见!")
break
if not user_input:
continue
if user_input.lower() in ("exit", "quit"):
print("再见!")
break
try:
result, messages = agent.chat(
user_input,
messages,
on_think=on_think,
on_tool_result=on_tool_result,
)
print(result)
except Exception as exc:
print(f"[错误] {exc}", file=sys.stderr)整体结构很薄,只做四件事:
解析命令行参数:
--provider选 openai / anthropic加载工具:
import内置工具模块触发自动注册创建 Agent:按 provider 实例化对应模型,挂上全部工具
对话循环:读输入 →
agent.chat(..., on_think=..., on_tool_result=...)→ 打印结果
回调函数的输出设计:
> 列出当前目录
💭 我应该使用 shell 工具执行 ls 命令来查看文件列表
🤔 调用工具: shell({"command": "ls"})
✅ 工具 [shell] 完成: {"stdout": "main.py\nodd\n...", "s...
当前目录包含 main.py、odd、scripts ...💭:思考过程(截断到 120 字符,防刷屏)🤔:工具调用意图(截断到 80 字符)✅:工具执行成功(截断到 60 字符)❌:工具执行失败(显示完整错误信息)
缩进两个空格,和最终的顶格输出形成视觉层次。
学到的要点
状态外置 = 上下文记忆:
chat()不自己持有历史,而是由调用方传入/接收。这样 Agent 本身保持无状态,同一实例可以被多个对话复用。回调比继承更灵活:想让 Agent 支持可观测性,加回调参数是最小侵入的方式。继承重写虽然也行,但会复制核心逻辑,维护成本更高。
不同 API 的思考内容位置千差万别:OpenAI 的 reasoning 在
message.reasoning_content,Anthropic 的 thinking 在独立的 content block,还有模型直接把推理塞在<think>标签里。做可观测性时必须逐一适配。CLI 体验要分层:最终答案顶格输出,中间过程缩进显示。人类一眼就能区分"这是 Agent 在干活"和"这是 Agent 给我的答复"。